ScrapeStorm으로 Amazon 특가 가구 상세페이지 정보를 빠르게 수집하는 방법 | 웹 스크래핑 툴 | ScrapeStorm
개요:이 글에서는 ScrapeStorm으로 Amazon 특가 가구 상세페이지 정보를 빠르게 수집하는 방법을 소개합니다. ScrapeStorm무료 다운로드
오늘은 이 튜토리얼을 통해 ScrapeStorm의 스마트 모드를 사용하여 Amazon 특가 가구 상품 상세 정보 스크래핑하는 방법을 알려드리겠습니다. 4단계 간단한 작업만 필요하고 AI가 번거로운 정보 스크래핑을 도와드릴 수 있습니다. 그럼 이제 구체적으로 어떻게 작동하는지 보여드릴게요~
1.태스크 만들기
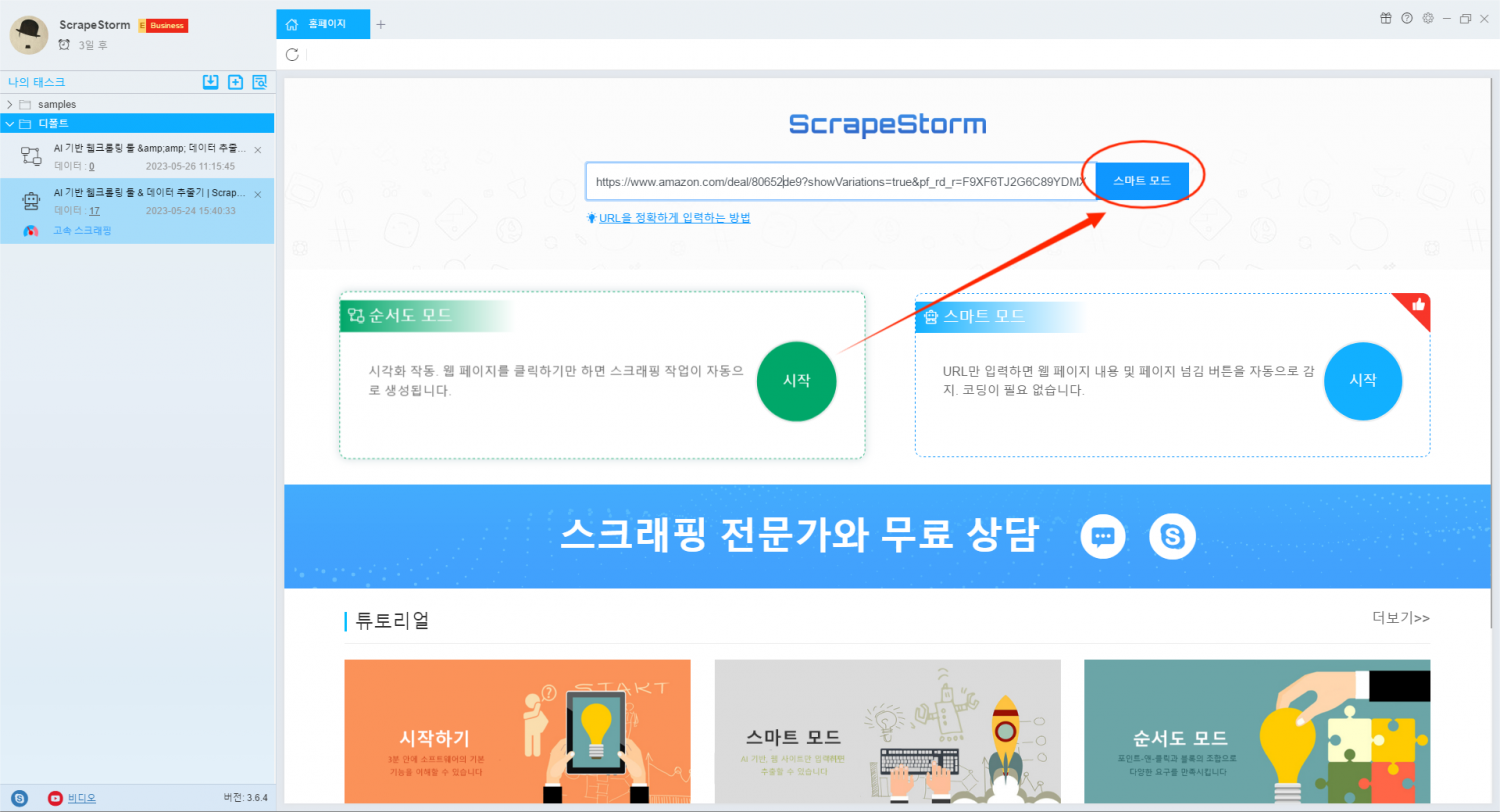
ScrapeStorm은 ‘스마트 모드’ 또는 ‘순서도 모드’ 를 선택하여 스크래핑 태스크를 생성할 수 있습니다. 여기에서 우리는 가장 많이 사용되는 순서도 모드를 사용하여 스크래핑 태스크를 만듭니다. Amazon 특가 가구 웹 사이트 주소를 텍스트 상자에 복사하고 오른쪽에 있는 ‘스마트 모드’ 버튼을 클릭하여 스마트 모드 스크래핑 태스크를 만듭니다.
2.태스크 설정하기
태스크를 만든 후 소프트웨어는 현재 리스트 페이지의 데이터를 자동으로 식별하고 필요에 따라 필드를 조정할 수 있습니다. 여기 소프트웨어는 이미 페이지에 있는 제목, 제목 링크, 가격등의 데이터를 자동으로 인식했습니다.
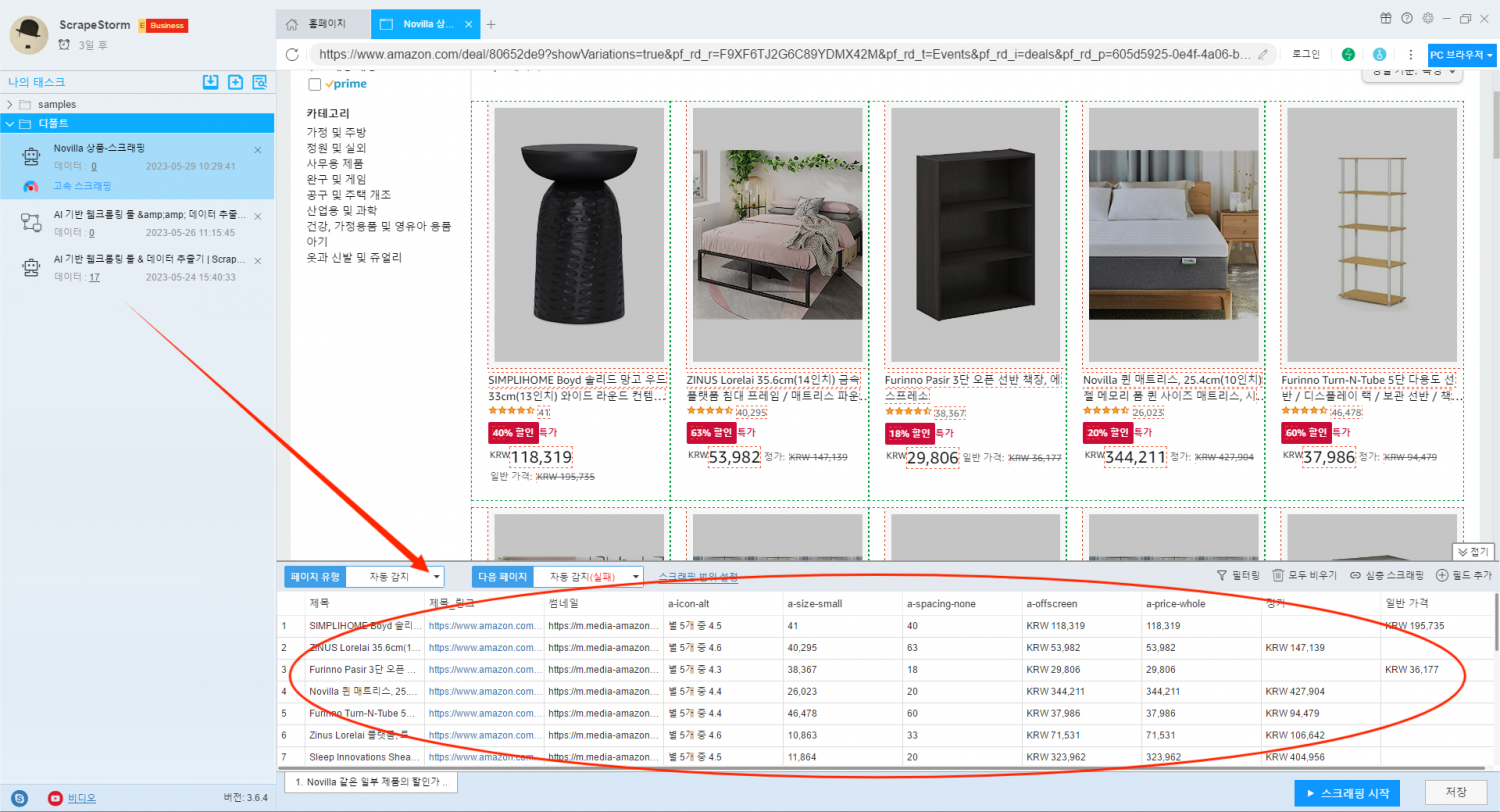
상품 세부 정보 페이지를 스크래핑하려면 심층 스크래핑을 사용해야 하며 ‘심층 스크래핑’ 버튼을 클릭합니다.
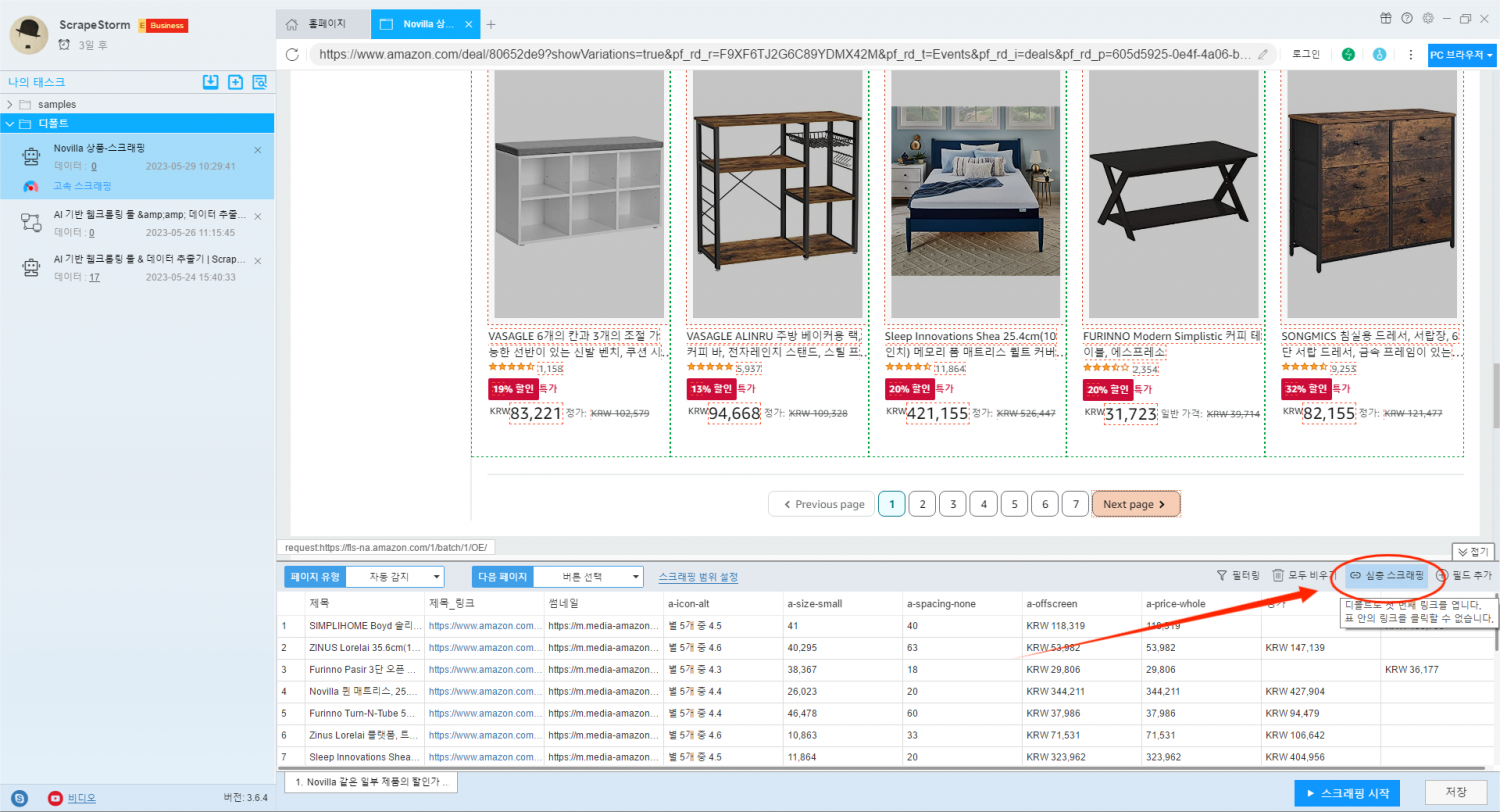
‘심층 스크래핑’ 버튼을 클릭하면 상세 페이지 인터페이스에 자동으로 들어가고 소프트웨어가 웹 페이지를 자동으로 인식하여 해당 필드를 자동으로 생성합니다. 아래 사진은 인식 완료된 상태입니다.
수집해야 할 필드를 남겨두고 수집 요구 사항이 없는 필드의 경우 필드를 선택하여 ‘삭제’ 를 마우스 오른쪽 단추로 클릭합니다.
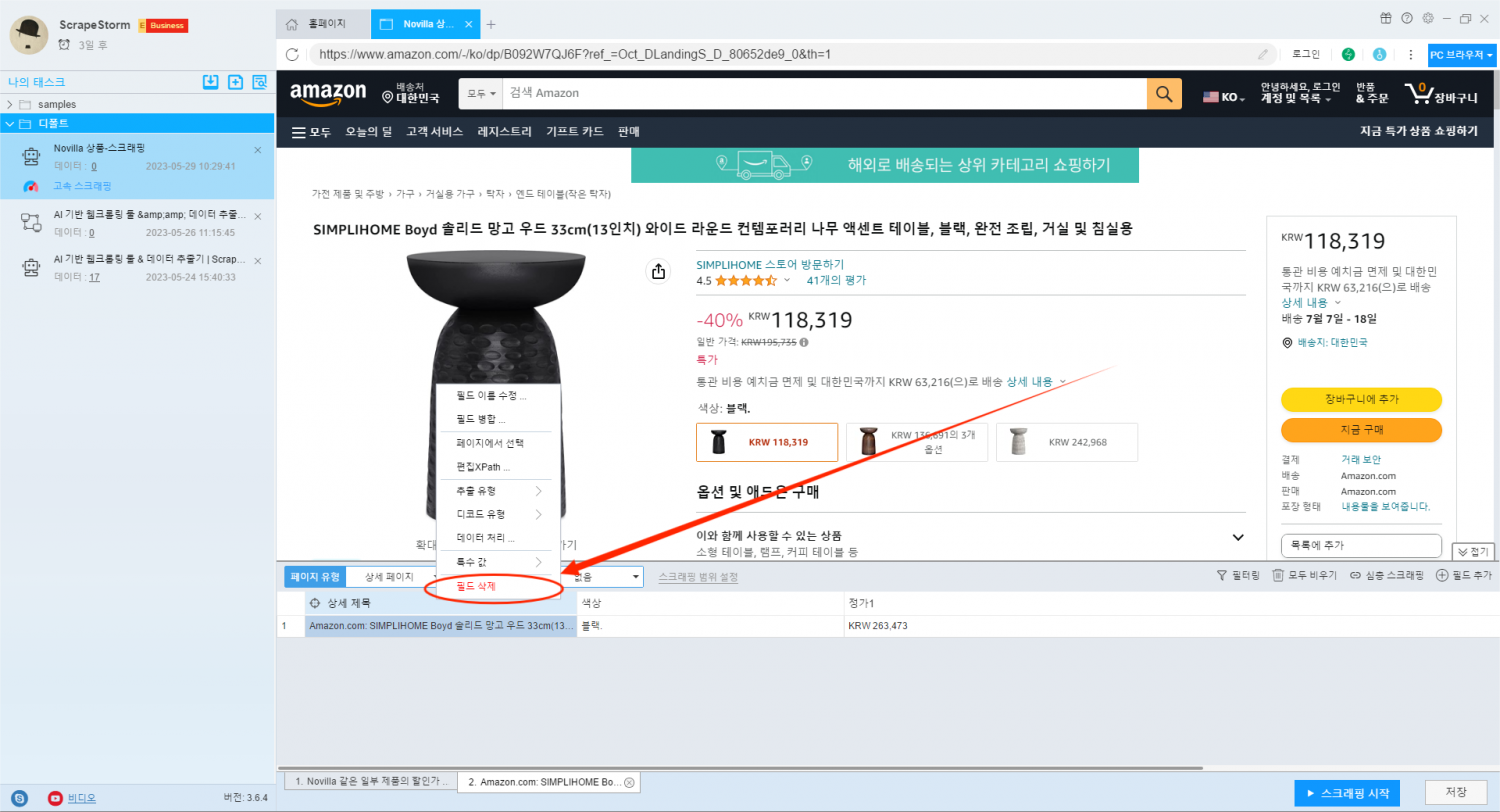
필드의 선택 범위를 변경해야 하는 경우 필드를 마우스 오른쪽 단추로 클릭하고 ‘페이지에서 선택’ 을 클릭하여 필드의 선택 범위를 변경할 수도 있습니다.
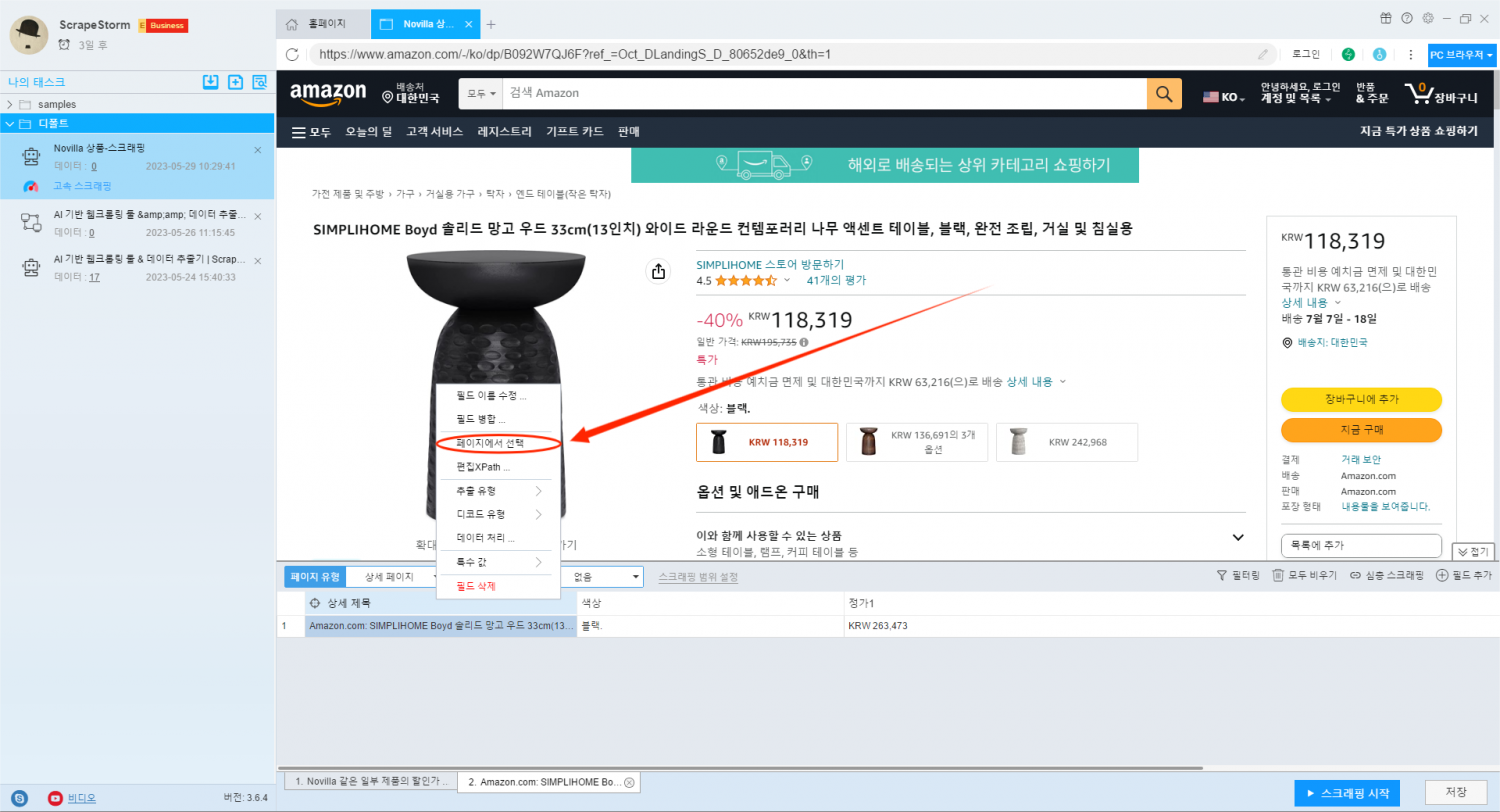
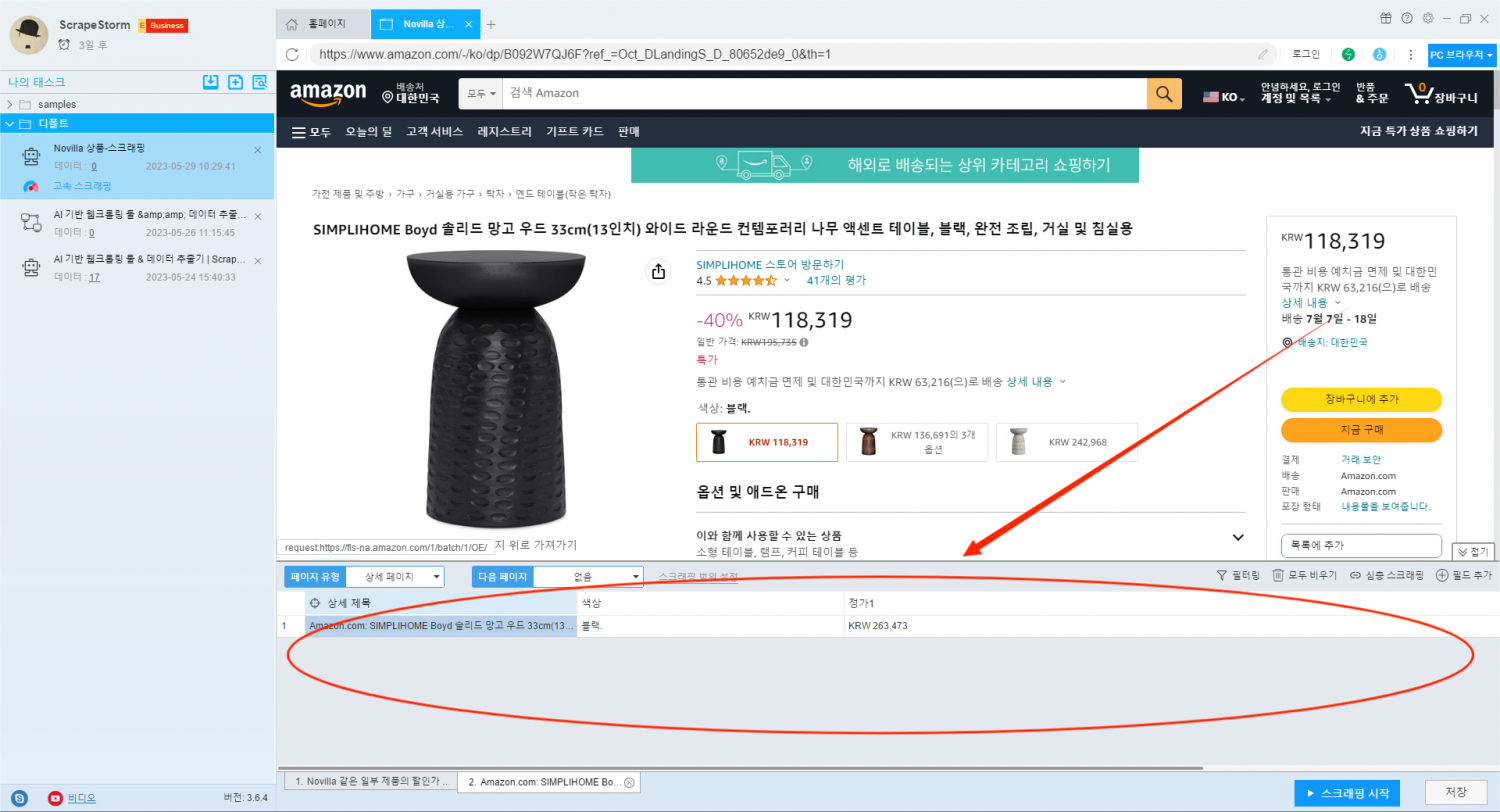
수집의 필요에 따라 필드를 수동으로 추가할 수도 있습니다. 여기서 상품 상세페이지의 첫 번째 리뷰 정보를 수집합니다. ‘필드 추가’ 버튼을 클릭하여 리뷰 정보를 선택하면 해당 필드를 생성할 수 있습니다.
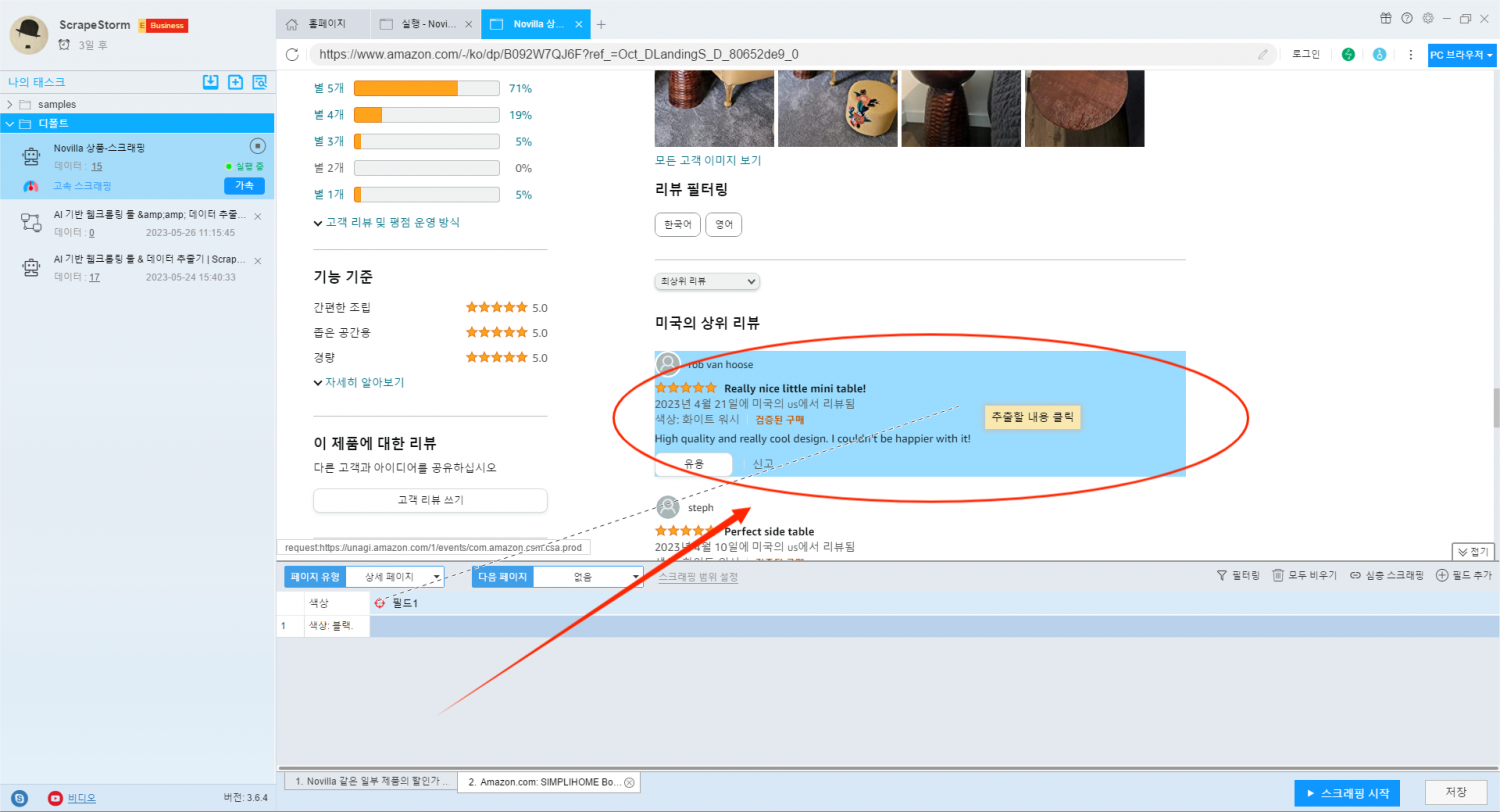
3.태스크 시작하기
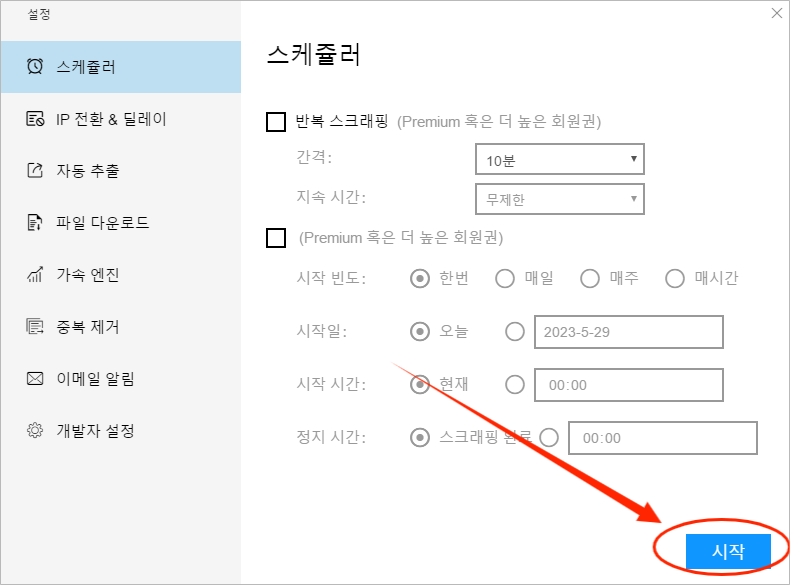
필드 설정을 완료한 후 ‘ 스크래핑 시작 ‘ 버튼을 클릭하면 구체적인 스크래핑 조건을 설정할 수 있습니다.스케쥴러, IP전환 딜레이, 자동 추출, 파일 다운로드 등 다양한 기능 설정을 포함합니다. 설정이 완료되면 ‘시작’ 버튼을 클릭하여스크래핑 태스크를 시작할 수 있습니다.
스크래핑 태스크가 실행되는 동안 ‘페이지 보기’ 를 클릭하면 실시간으로 수집 중인 웹 인터페이스를 볼 수 있습니다.
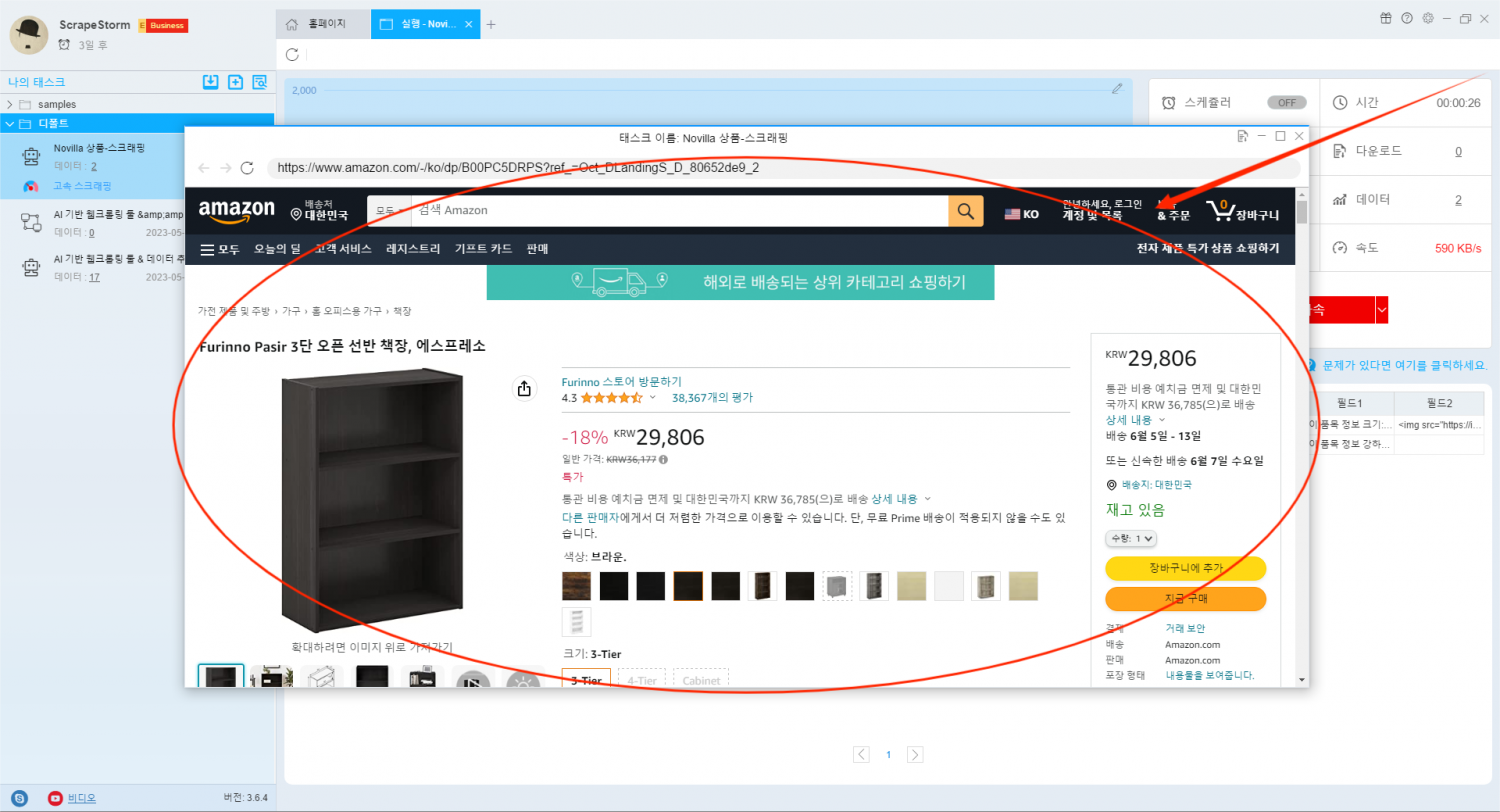
4.데이터 내보내기
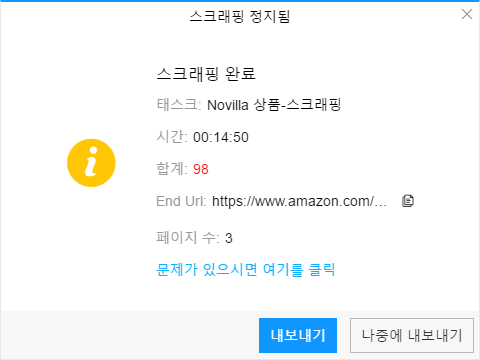
모든 데이터가 수집되면 소프트웨어가 자동으로 힌트를 보내므로 ‘내보내기’ 거나 ‘나중에 내보내기’ 버튼을 선택할 수 있습니다.
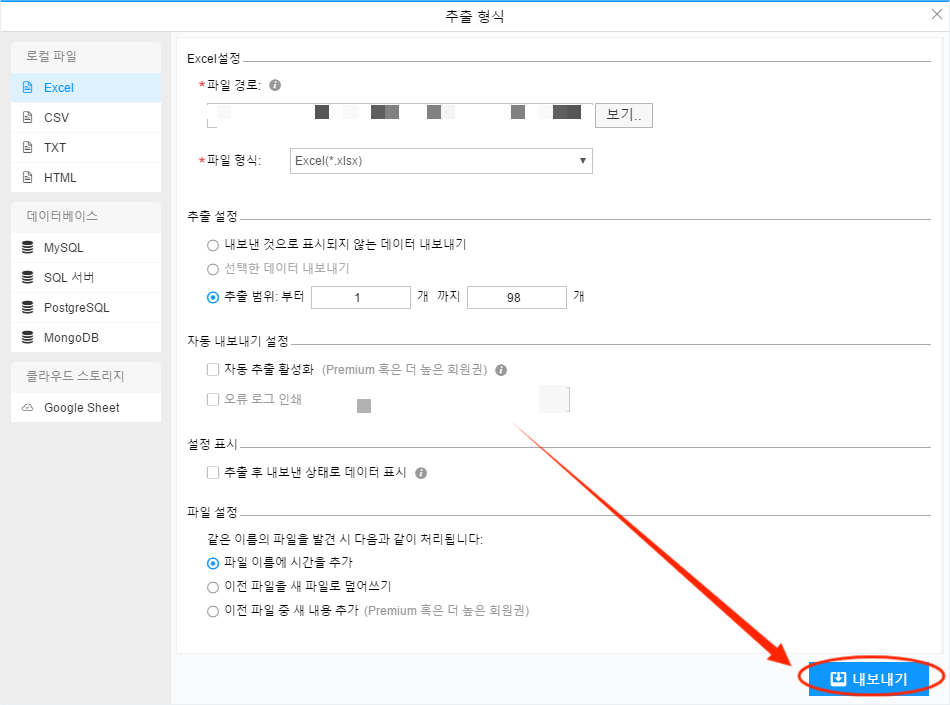
내보내기 유형에는 Excel, CSV, TXT, HTML 및 데이터베이스 MySQL, SQL Server, PostgreSQL, MongoDB, 그리고 Google Sheet가 포함되며 필요에 따라 적절한 데이터 내보내기 유형을 선택하시면 됩니다.
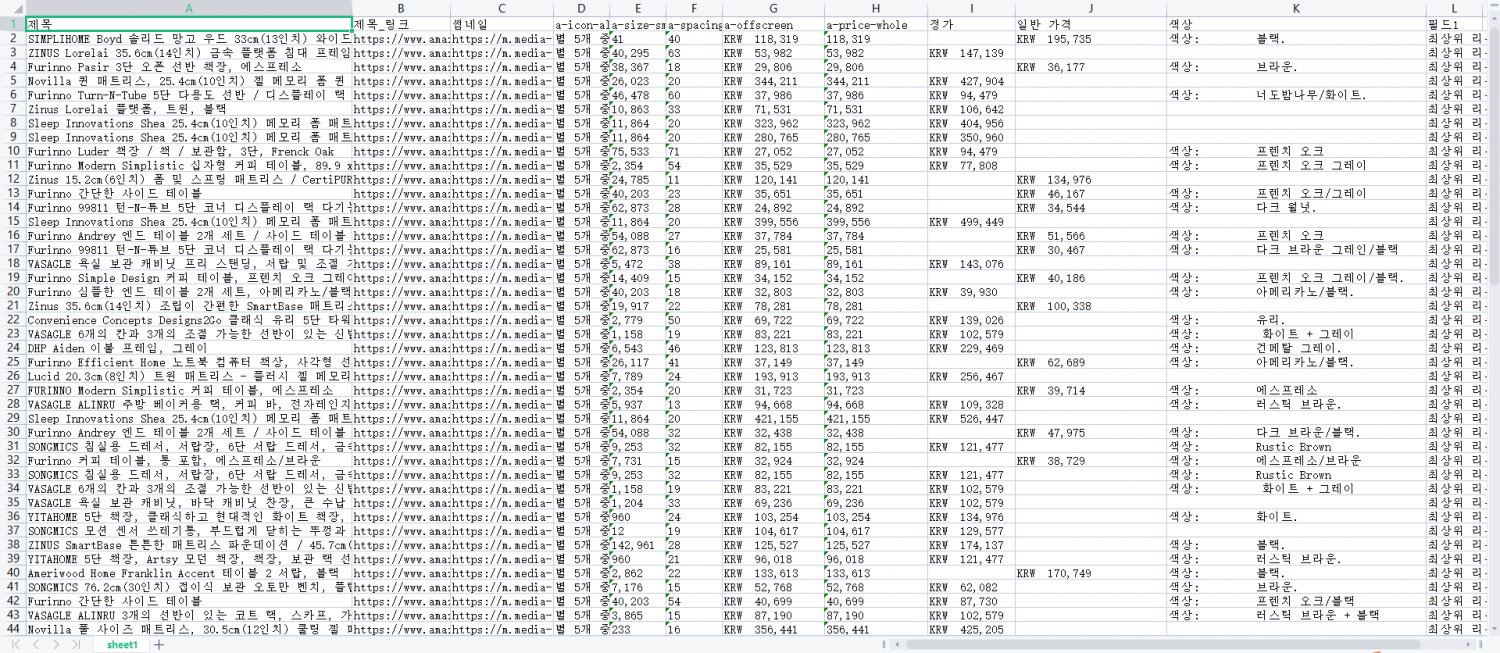
아래의 사진은 Excel로 내보낸 데이터 스크래핑 결과입니다.
ScrapeStorm을 이용하여 Amazon 상품정보 상세정보 수집은 조작이 간단할 뿐만 아니라 비용이 들지 않습니다. ScrapeStorm 클라이언트를 다운로드하기만 하면 웹 정보 수집이 자유로워집니다. 튜토리얼을 보신 분들도 빨리 와서 해보시죠~^^
면책 성명: 이 글은 우리 사용자에 의해 기여되었습니다. 침해가 발생한 경우 즉시 제거하도록 조언해 주세요.